This song was created using a custom AI transformer model that was trained using piano renditions of pop and soft rock music. The goal of this project was to experiment with leveraging generative AI and transformer networks to create human sounding music. The dataset contains 152,000+ songs in total, including synthetically generated samples, and the network weighs in at about 80M parameters.
Pianist Lera Palyarush (@lera.palyarush)
Makeup artist Ilya Adamov (@adam_off)
Video operator Miroslaw Tarabanowski (@tarabanowski)
Project coordinator Taras Demianchuk (@demt)
The model was trained using the transformer design described in Attention is All You Need, with a few simple modifications, described below.
The Dataset:
The dataset consists of midi files scraped from the web (see fetch.py) and then filtered based on a few simple heuristics (e.g. dominant chord progressions, attribute variance) designed to focus the model on the styles of pop and soft rock music. This includes
publicly available samples indexed by Google, as well as samples from popular midi datasets (e.g. Maestro, POP909, NMD,
Muse) that fit the criteria.
Once the base sample set is gathered, we use it to synthesize many more samples, again using a few basic rules from music theory (e.g. chord inversions, reduction). We do not incrementally shift pitches,
as this would not teach new musical patterns and increases training complexity. Instead, we normalize pitches (see below) during both training and generation.
Pre-processing:
Midi files are converted to "abc" files, which describe notes and chords using alpha-numeric encoding (e.g. a#5c5g5) plus timing information (offset/step and duration). During this conversion we normalize the pitches (center pitch, octave spread), as well as filter out timing data that's shorter than a threshold.
This process reduces the number of unique tokens that need to be learned, and helps densify the dataset. We then calculate a token dictionary of the top_k most common notes/chords. After experimentation, I settled on k=5000 for pitch, and k=1000 for timing attributes,
as these values seemed to offer a reasonable tradeoff in accuracy,
performance, and model quality.

Many midi files lack proper instrument names, so we prioritize piano and piano-similar instruments (for our piano model) but use basic fallback logic if none are present. I spot check a very small random sample (around 20 to 30 songs) to get a rough sense for whether the synthetic content sounds reasonable.
Training:
A simple learning rate scheduler is used to maintain a reasonable progression over time.
Relative positional embedding is used to more effectively capture proximal attention between note pairs.
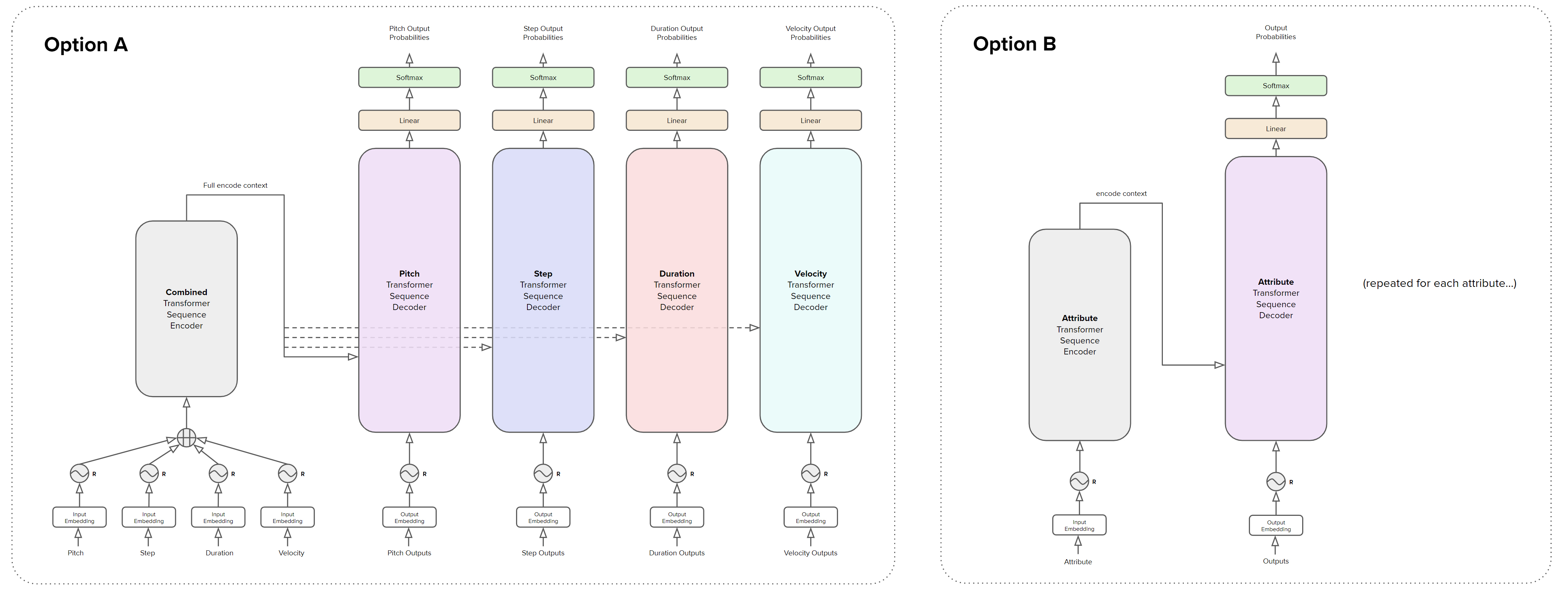
Gaussian error linear unit (gelu) is used, in place of a rectifying linear unit (relu). Pitch, offset, duration, and velocity are learned independently.
The network topology uses a full transformer for each attribute (pitch, step, etc.) in parallel (Option B), with transformer complexity adjusted indepdendently to find the best configuration for each attribute. I experimented with a couple of other designs (e.g. Option A),
but ultimately settled on a design that simplified the training complexity enough to finish training with reasonable quality in about 16 hours on a single GPU.
Generation:
Given a song intro (N or more tokens), the network effectively learns to complete the piece (up to 512 tokens by default, generally around 2 minutes of playtime).
If given a prompt that closely matches a sample from the training set, the network will generally reconstruct the sample.
Temperature and top_k are used to control how much expression the system uses when generating notes. By default, temperature and top_k are set to 1, which
selects the prediction with the highest softmax probability. Most importantly, like most generative AI, achieving quality output depends heavily on the input and lots and lots of iteration.
Similar to training, we normalize input samples for generation. It's possible that a sample song may contain chords or timing data that the model hasn't seen. In these cases we
replace unknown values with their nearest represented token (e.g. a#5d5f4d3 may be reduced to a#5d5f4).
Post-processing:
With encouragement, the AI generates music with interesting chord progressions, patterns, and motifs. However, it can also easily generate fairly terrible music. After some trial and error and temperature tweaks, the AI may generate something I find interesting. The next step is to load the generated midi file into Logic Pro, apply VSTs (e.g. NI Grandeur Piano, Stradivari Violin) and apply post-processing. This may involve removing notes to help clarify themes, or modulating articulations (e.g. velocity, expression), as well as adjusting EQ and mastering.
Grab the source and model files (below) and place them in the same folder. Run install.sh to install the necessary python packages. Run generate.py to generate a new song by providing an input sample midi file. Run train.py to train a new model. Tweak the parameters at the top of these files to alter the way the project learns or generates music.
In the future this could be extended to support different instrument categories (beyond the current piano and strings) and used to generate more complex music (orchestral, beats, etc.). This is an exciting area of research, with progress happening rapidly across many fronts (e.g. Project Magenta)!
Want to hear more? Check out Serenity on Soundcloud, as well as a few other songs generated by this AI.
There are two flavors of the Serenity model: a lite version (24M parameters) that was trained using 16k verifiably permissible music samples, and a full version (80M parameters) trained off of a much larger data set that was scraped from the publicly accessible web.
Only the lite version of the model is available for download at this time.
Lite piano model checkpoint (261 MB)
Transformer source code (Python + Tensorflow)
