Sunday, January 9th, 2011
Compression is the process of reducing the storage space requirement for a set of data by converting it
into a more compact form than its original format. Huffman coding is one of the most well known compression schemes and it dates back to the early 1950s, when David Huffman
first described it in his paper,
"A Method for the Construction of Minimum Redundancy Codes."
Huffman coding
works by deriving an optimal prefix code for a given alphabet that reduces the cost of frequent symbols, at the expense of less common ones. Let's walk through a simple example that demonstrates the process of building a Huffman code.
Let's assume we have an alphabet, G, which consists of all possible symbols in a data set. In our example, G contains precisely four symbols: A through D.
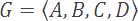
We also have a probability density function, P, which defines the probabilities for each symbol in G actually occurring in an input string. Symbols with higher probabilities are more likely to occur in an input string than symbols with lower probabilities.
A prefix code ascribes a numerical value to each symbol in an alphabet such that no symbol's code is a prefix for any other symbol's code. For example, if 0 is the code for our second symbol, B, then no other symbol in our alphabet may begin with a 0. Prefix codes are useful because they enable precise and unambiguous decoding of a bit stream.
Building the code
The process for deriving an optimal prefix code for a given alphabet (the essence of Huffman coding) is straightforward. We begin by selecting the two symbols of our alphabet with the lowest probabilities, and create two leaf nodes as follows:
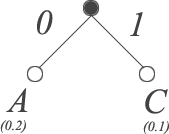
We assign the left path a value of 0, and the right path a value of 1. Next, we connect our new parent node with the next lowest probability symbol, to arrive at the following tree:
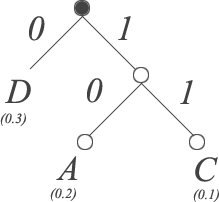
We continue this process until all symbols have been inserted into the tree. Note that it doesn't matter whether we attach symbols to the left or right child. Once we've included all symbols from our example alphabet we arrive at the following:
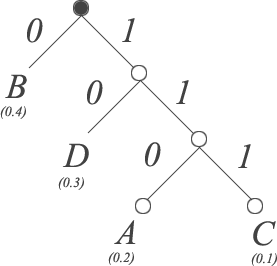
To compute the Huffman code for any symbol in our tree we simply traverse the tree from root to the symbol, and take note of which edges we use in our path. For example, the symbol A requires us to traverse 110 to reach that node. The following table illustrates the Huffman codes for all symbols in our alphabet.

Advanced Techniques
Huffman codes provide a simple but efficient coding scheme for our basic model. For more complicated models there are two popular enhancements to this algorithm:
Adaptive coding: adaptive Huffman coders will dynamically update the symbol probabilities, and thus the Huffman codes themselves, based on the data seen so far. This allows the coder to more effectively handle data streams with uncertain or shifting probabilities.
Extended Huffman codes: alphabets with a large number of symbols may reduce the efficiency of using basic Huffman codes. To cope with this, coders may group symbols together to create extended Huffman codes. This can reduce the total number of symbols in the alphabet by taking advantage of structure level similarities in the stream.
Further Reading
Check out some of my other compression related blog posts including:
Fundamentals of Compression
Context Adaptive Binary Arithmetic Coding
Primitive Texture Compression
Thanks for reading!
